얼마 전까지 회사에서 Google map API를 사용해서 지리정보를 표현해야 하는 기능을 만들었습니다.
많은 사람들이 사용하는 API라 큰 고민 안하고 사용하면 될 줄 알았는데, 무지성으로 사용하다 보니 역시 성능이 걸림돌이 되더군요.
마커의 개수가 많아지다 보니, 지도를 불러오는데 시간이 엄청걸리더니 급기야 응답이 없는 상황까지 이르렀습니다.

오늘은 이 지도위에 마커를 표현할 때, 효율적으로 표현할 수 있는 방법에 대해서 다룰까 합니다.
굉장히 쉽고 일반적이면서, 효과를 많이 볼 수 있는 방법들 위주로 3가지를 소개하려고 합니다.
- 마커클러스터 이용하기(필수)
- 뷰포인트(혹은 중심점)을 기준으로 반경 몇 km 내 마커만 로드하기(필수)
- 공간DB(Geography) 쿼리 이용하기(선택)
1. 마커클러스터 이용하기
대부분의 지도 API들이 가지고 있는 기능이기 때문에, 쉽게 구현할 수 있습니다. 하지만, 그 효과는 엄청납니다.
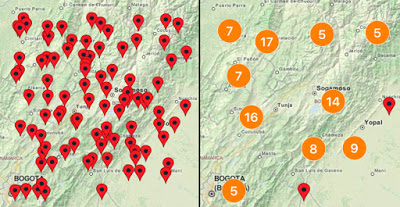
지도 위에 찍어야할 마커 수가 500개 이상이라고 가정해 봅시다. 지리정보를 이용하는 사용자는 너무 많은 마커 때문에 오히려 본인이 원하는 지역의 마커를 식별하기 어려울 것입니다. 심지어는 마커들끼리 겹치는 마커충돌현상(marker collision) 현상이 일어나기도 합니다.
마커클러스터를 이용하면 이러한 문제를 해결할 수 있습니다.
마커클러스터는 일정 지역 가까운 마커를 묶어 하나의 그룹으로 표현하며, 해당 그룹 내에 얼마나 많은 마커가 있는지 명시적인 숫자로 표기해줍니다.
우리가 방을 알아볼 때, 사용하는 대표적인 지리정보 시스템인 직O, 다O도 이런 식으로 구현되어 있죠.
마커클러스터 이외에도
Marker Spiderfier라고,

특정 클러스터를 클릭하면, 마치 거미다리 뻗듯이 여러 갈래로 마커를 표현하는 기능도 있는데,
요는 여러마커를 하나의 그룹으로 묶어준다는 것입니다.
지도 위에 마커를 표현한다면, 반드시 추가해야 할 필수 기능이라고 보시면 됩니다.
2. 뷰포인트(혹은 중심점)을 기준으로 반경 몇 km 내 마커만 로드하기
이 포스팅을 쓰는 이유이기도 한데요.
위에서 마커클러스터를 사용했음에도 여전히 성능 저하는 발생할 수 있습니다.
제가 간과한 부분이기도 했고요,,
한 번에 로드해야되는 마커의 개수가 충분히 많다고 하면, 아무리 마커클러스터를 쓴다한들 성능은 크게 개선되지 않을 것입니다.
이제는 "한 번에 로드해야되는 마커의 개수"를 줄여야할 필요가 있습니다.
전 세계를 대상으로 학교를 표기하는 지리정보 시스템이 있다고 가정해 봅시다.
우리는 과연 "한 번에 전 세계에 있는 학교들에 대한 정보"를 가져올 필요가 있을까요??
지리정보를 이용하는 이용자는 아무리 넓게 본다한들 하나의 국가 이상으로는 데이터를 식별하기 어려울 것입니다.
그렇다면, 지금 사용자가 보고있는 국가 혹은 지역의 마커들만 로드한다면 크게 성능을 개선할 수 있을 겁니다.
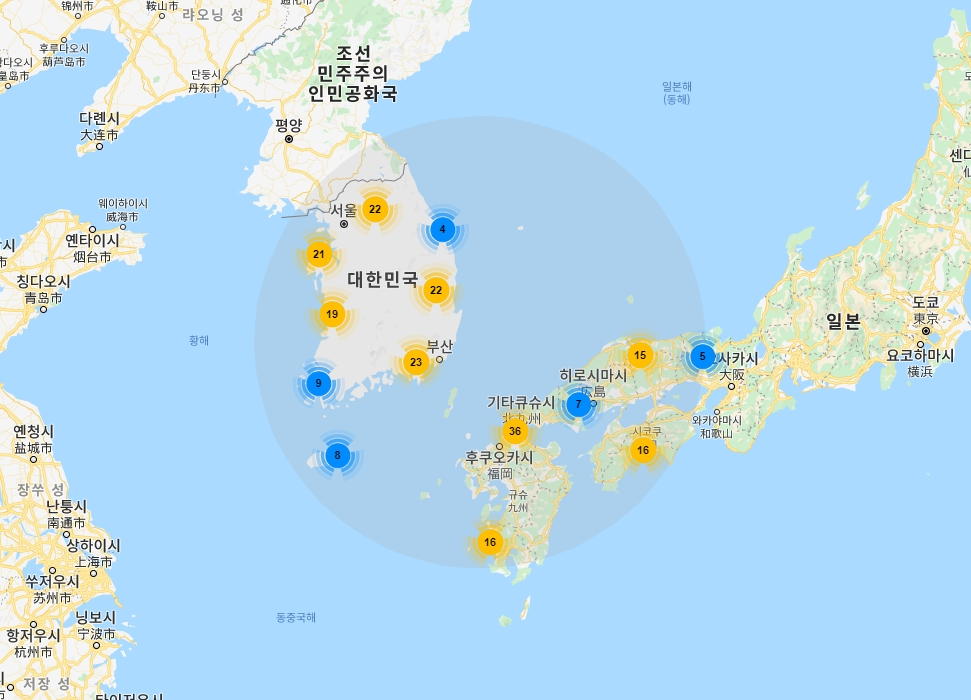
가령 중심점을 기준으로 반경 500km 내에 마커를 로드한다면, 전 세계에 있는 모든 마커를 로드할 필요 없이 해당 반경 내에 필요한 마커를 지도를 이동해가며 얻어올 수 있습니다.
위 기능을 사용하려면 지도 위에 중심점의 좌표(Reverse geocoding)를 얻어올 수 있어야 하고, 지도 이동완료 이벤트(Mouse over event)를 감지할 수 있어야 합니다.
지도 이동 event가 발생할 때마다 지도의 중심점을 Reverse geocoding으로 위/경도 좌표값으로 얻어낸 후, 중심점을 기준으로 반경 500km 내의 마커를 데이터베이스에서 조회해 프론트로 넘겨주는 것이죠.
이때, 반경 몇 km인지 알아낸는 방법은 Harversine 공식을 이용하거나 공간DB의 distance쿼리를 이용하는 방법을 사용합니다. 공간DB활용은 잠시 뒤에 다룰 것이니 Harversine 공식에 대해서 알아보겠습니다.

Harversine 공식을 사용하면, 지구상에 두 지점 사이의 거리를 구할 수 있습니다.
위 공식을 사용해서 중심점과 특정마커 사이에서 나온 distance가 설정한 반경 500km 내라면 지도에 표현할 마커로 선택하는 것이죠.
이 방법 역시 마커를 지도에 표현한다면 필수로 사용해야 할 기술입니다.
3. 공간DB(Geography) 쿼리 이용하기
마지막으로 공간DB를 활용하는 방법입니다.
DB종류에 따라서 지원하지 않는 DB도 있으나 대표적인 RDB인 MySQL, MSSQL은 지원한다고 합니다.
일반 쿼리에 비해선 다소 어려우나 차근차근 문법을 뜯어보면 그리 어렵지 않습니다.
공간DB에는 Geometry와 Geography가 있는데,
Geometry는 기하표현에서 사용하고 Geography 지구 상에 지리정보에서 사용하니 용도에 맞게 사용하면 될 것 같습니다.
우리는 지리정보에 관심이 있으니 Geography를 활용하겠습니다.
중심점(Origin)을 기준으로 반경km 내 마커를 구하는 쿼리는 아래와 같습니다.
select * from School s
where Geography::Point(:{origin.x}, :{origin.y}, 4326).STDistance(s.geoLocation)
<= :distance
2번째 줄 부터 조건을 보면 입력으로 받은 중심점(origin)을 point로 변환한 다음,
School테이블에서 geography 타입으로 생성한 컬럼과의 거리를
STDistance라는 계산식을 사용해 구해냅니다.
그 후, 3번째 줄에서 우리가 설정할 반경 거리를 조건을 겁니다.
공간DB는 필수까진 아니지만, geography라는 type으로 2차원적 인덱싱이 가능하니,
조건에 맞는 마커를 구할 때 테이블 풀스캔을 피하고 싶다면 활용하는 편이 좋을 것 같습니다.
이상으로 포스팅을 마치겠습니다.